The First Shared task on Aggression Identification was organised in conjunction with the First Workshop on Trolling, Aggression and Cyberbullying. The idea of the shared task was fairly simple. Classify a text in one of the following three categories: Overtly Aggressive (OAG), Covertly Aggressive (CAG) and Non-aggressive (NAG). This means that the task is essentially a standard text categorisation task and an approach based on bag-of-words is a good baseline to start with (neither me, nor the task organisers provided a baseline based on bag-of-words, so I don’t know what is the accuracy of the method).
My approach for this task was to use word embeddings to calculate features which are used to train machine learning algorithms. My paper:
Constantin Orǎsan (2018) Aggressive Language Identification Using Word Embeddings and Sentiment Features. In Proceedings of the First Workshop on Trolling, Aggression and Cyberbullying (TRAC-2018), p. 113 – 119, Santa Fe, USA, August, 25, http://aclweb.org/anthology/W18-4414
as well as the GitHub repository which contains the code, provide more details about the approach employed. You can also find the notebook below. However, one thing I found interesting is the relative high performance of the method given how simple it is.
I tried the same method in the WASSA 2018 Implicit Emotion Shared Task (IEST), but its performance was very poor. I thought the task can be modelled very much the same way: given a bunch of words, predict a class. Not only that the method worked poorly, but in order to obtain better results, I had to consider only a window of three words on each side of the word (class) to predict. Probably this does not make much sense if you are not familiar with IEST. Due to lack of time and poor results, I did not prepare a paper describing the results. However, I hope to get back to this task and investigate word embeddings more.
Aggressive Language Identification Using Word Embeddings and Sentiment Features
This notebook presents the code of my participation in the First Shared Task on Aggression Identification. More details about the approach can be found in:
Constantin Orǎsan (2018) Aggressive Language Identification Using Word Embeddings and Sentiment Features. In Proceedings of the First Workshop on Trolling, Aggression and Cyberbullying (TRAC-2018), p. 113 - 119, Santa Fe, USA, August, 25, http://aclweb.org/anthology/W18-4414
Abstract
This paper describes our participation in the First Shared Task on Aggression Identification. The method proposed relies on machine learning to identify social media texts which contain aggression. The main features employed by our method are information extracted from word embeddings and the output of a sentiment analyser. Several machine learning methods and different combinations of features were tried. The official submissions used Support Vector Machines and Random Forests. The official evaluation showed that for texts similar to the ones in the training dataset Random Forests work best, whilst for texts which are different SVMs are a better choice. The evaluation also showed that despite its simplicity the method performs well when compared with more elaborated methods.
The first step is to import all the necessary modules:
%%capture --no-display
# the previous line is to suppress warning caused by using deprecated functions in numpy
# in this case it's safe to ignore them
import csv
import re
import emoji
import nltk
import math
import numpy as np
from nltk.tokenize import word_tokenize
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
from sklearn.metrics import f1_score
Initialise various variables
# debug is used to supress various warnings and debugging messages
debug = False
# path to training and dev data. You can obtain the data from the workshop organisers.
path_to_data = "english/"
The purpose of the task was to classify short texts into three categories Overtly Aggressive (OAG), Covertly Aggressive (CAG) and Non-aggressive (NAG).
labels = ['NAG', 'CAG', 'OAG']
Step 1: Load the data
def read_data(file_name, test_data=0):
'''
Reads the data from a CVS file. Each instance is stored in a tuple with the
structure (ID, text, label)
Returns a list which contains all the instances from the file
'''
data = []
with open(file_name, encoding = 'utf8') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
if test_data:
id_ex, text = tuple(row)
data.append([id_ex, text, "UNK"])
else:
id_ex, text, label = tuple(row)
data.append([id_ex, text, label])
return data
print("Reading the data ...", end="")
training = read_data(path_to_data + 'agr_en_train.csv')
dev = read_data(path_to_data + 'agr_en_dev.csv')
print("done!")
Reading the data ...done!
The data is now ready to be used.
# the second instance from the training data
print(training[1])
['facebook_corpus_msr_466073', "Most of Private Banks ATM's Like HDFC, ICICI etc are out of cash. Only Public sector bank's ATM working", 'NAG']
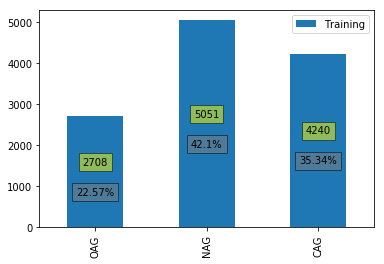
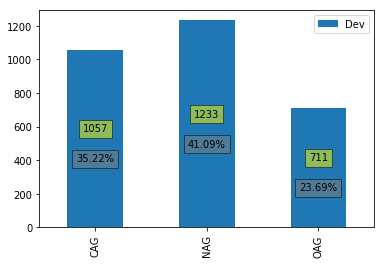
We can have a look at how the instances are distributed between different classes.
%%capture --no-display
%matplotlib inline
import matplotlib.pyplot as plt
from collections import Counter
from pandas import DataFrame
def plot_data(df):
ax = df.plot(kind='bar')
total = 0
for p in ax.patches:
total += p.get_height()
for p in ax.patches:
ax.annotate(np.round(p.get_height(),decimals=2), (p.get_x()+p.get_width()/2, p.get_height()/2),
ha='center', va='center', xytext=(0, 10), textcoords='offset points',
bbox=dict(facecolor='yellow', alpha=0.5))
ax.annotate(str(np.round(p.get_height()/total * 100,decimals=2)) + "%", (p.get_x()+p.get_width()/2, p.get_height()/2),
ha='center', va='center', xytext=(0, -20), textcoords='offset points',
bbox=dict(facecolor='gray', alpha=0.5))
# plot the training data
df = DataFrame.from_dict(Counter([instance[2] for instance in training]), orient='index')
df.rename({0: "Training"}, axis='columns', inplace=True)
plot_data(df)
# plot the dev data
df = DataFrame.from_dict(Counter([instance[2] for instance in dev]), orient='index')
df.rename({0: "Dev"}, axis='columns', inplace=True)
plot_data(df)
Step 2: Calculate the features
2.1 Features based on word embeddings
The main purpose of this method was to explore to what extent word embeddings can be used as features for traditional machine learning methods. For the experiments in the paper, I used the pretrained GloVe vectors from https://nlp.stanford.edu/projects/glove/
The experiments were run using glove.840B.300d.zip (vectors generated using 840B tokens from Common Crawl, 2.2M vocabulary size, cased, 300d vectors)
# path to the uncompressed GloVe vector
path_to_glove="/home/dinel/Projects/2018-aggression/glove/glove.840B.300d.txt"
def loadGloveModel(gloveFile):
'''
Loads the embeddings into a dictionary. This will consume lots of memory.
Returns the dictionary where the keys are the words and the values the embeddings
'''
print("Loading Glove Model")
f = open(gloveFile,'r')
model = {}
for line in f:
splitLine = line.split()
word = splitLine[0]
try:
embedding = np.array([float(val) for val in splitLine[1:]])
model[word] = embedding
except:
if debug: print("Problem:", line)
print("Done.",len(model)," words loaded!")
return model
# load the embeddings
embeddings = loadGloveModel(path_to_glove)
Loading Glove Model
Done. 2195884 words loaded!
# we can check the vector corresponding to a word
print(embeddings["hate"])
[-6.1052e-01 1.1656e-01 -5.0648e-01 -3.2216e-01 -9.9742e-02 1.0182e-01
3.1042e-01 -1.8155e-01 3.1774e-01 2.1537e+00 -8.1129e-02 -3.8734e-01
6.8008e-02 -5.8029e-03 -5.3814e-01 -9.8787e-02 -8.4160e-02 3.1755e-02
-2.9811e-01 5.0496e-01 4.1719e-01 1.1462e-01 2.5330e-01 -1.6668e-01
2.6645e-02 4.5709e-02 -5.9685e-01 -3.9645e-01 4.3089e-01 1.3014e-01
-4.0591e-02 6.6024e-01 -5.3007e-01 -8.1629e-02 3.3484e-01 1.6258e-01
3.9029e-02 7.2786e-02 -1.8635e-01 3.8104e-01 -5.0557e-01 -3.0910e-02
-3.2578e-01 3.8818e-01 1.4605e-01 3.8982e-02 -1.4992e-01 6.0316e-01
-3.0801e-02 1.3456e-01 -6.2982e-01 5.8746e-02 1.5878e-02 -7.8831e-02
1.4754e-01 5.2191e-02 -4.3654e-01 -1.6707e-01 -1.5184e-02 -1.6073e-01
-2.1243e-02 8.3719e-02 -6.5062e-01 -7.9566e-02 -4.5479e-02 -1.0070e-01
-1.4044e-01 -4.1403e-02 1.2033e-01 2.6015e-03 1.0318e-02 1.2444e-01
3.0785e-01 -2.4270e-01 4.9056e-02 2.1891e-01 1.5346e-01 1.6682e-01
5.0732e-01 5.9128e-01 -3.0452e-01 -5.8077e-02 1.4405e-01 -4.4923e-01
2.3952e-01 -1.8347e-01 2.6224e-01 -7.6430e-01 1.1990e-01 -4.5683e-01
-1.4176e-01 -1.6581e-01 1.2650e-01 2.3494e-01 2.1847e-01 1.2909e-01
4.9598e-02 4.8204e-01 -1.7446e-02 -3.5697e-01 3.1545e-01 -2.6209e-01
-3.4744e-02 -4.2803e-01 5.4802e-01 -7.5777e-01 -1.6709e-01 -2.3587e-02
-2.7345e-01 9.4488e-02 -9.8469e-02 -2.5598e-01 2.9519e-02 -4.2601e-01
-2.5830e-01 -1.1096e-02 1.1266e-01 -5.7712e-01 -1.4331e-01 -4.8758e-02
8.4046e-02 -1.4820e-01 6.3360e-02 -5.2884e-01 5.1334e-01 5.5074e-02
3.3447e-01 -4.5821e-02 -8.4835e-02 5.3418e-02 -6.0270e-01 1.0075e-01
3.4882e-02 1.3661e-01 -5.7156e-02 -3.2932e-01 -5.0855e-01 -1.0988e-01
8.5876e-02 -1.2094e-01 -2.9525e+00 -9.1559e-02 4.1377e-01 2.9983e-02
-4.5670e-01 3.1407e-01 -2.9968e-01 4.8521e-02 -5.2216e-01 -6.1831e-01
3.2831e-01 2.2728e-01 2.7956e-01 1.3687e-01 -3.8543e-02 2.9034e-01
-1.5775e-01 -6.1231e-01 -4.9361e-02 1.4326e-01 -2.3045e-01 5.2664e-02
9.3194e-02 2.7935e-01 -1.8719e-01 4.2922e-01 -1.2092e-01 -3.3848e-02
-6.7490e-01 -4.7605e-01 -3.0468e-01 -2.6370e-01 2.5106e-03 -4.6804e-01
6.8331e-01 1.6012e-01 -5.1522e-01 1.8021e-01 2.5192e-01 -3.2158e-01
-2.5619e-02 -3.0824e-01 -6.2287e-01 8.0491e-02 -2.8676e-02 2.4823e-01
6.2337e-02 -4.3325e-01 5.4157e-01 1.4867e-01 2.3373e-01 -4.6265e-01
-2.9033e-01 -2.1299e-01 3.3593e-01 6.8914e-02 2.4089e-01 -3.2855e-01
-1.5312e-01 3.4413e-01 3.3486e-02 -5.7180e-02 9.8070e-02 -4.4647e-02
3.5703e-01 -3.5915e-01 7.0520e-02 7.5669e-02 1.6122e-01 1.5627e-01
-8.8761e-02 5.2585e-01 2.7204e-01 3.4040e-01 7.6718e-02 5.6750e-03
-2.9162e-01 -1.6033e-01 -3.9822e-01 -3.8824e-02 8.5246e-03 4.1401e-02
-2.2201e-01 -2.9588e-01 -7.4356e-02 6.3065e-02 5.1414e-02 -1.1666e-01
-2.0297e-01 -3.3333e-01 -5.7485e-01 1.0103e-01 -1.3429e-01 -5.7319e-02
-7.3142e-02 -1.7734e-01 6.7575e-01 -7.7484e-02 2.9055e-01 3.8863e-01
5.1169e-02 3.3529e-01 1.1840e-01 -7.4655e-03 -2.2907e-01 2.0701e-01
-2.4925e-01 5.5953e-02 -1.5499e-01 5.6069e-01 -6.4385e-02 -3.0198e-02
-7.5703e-02 -1.9910e-01 -2.2604e-01 -3.7639e-02 -2.0899e-01 -8.6741e-02
-2.2423e-01 1.9680e-01 5.7717e-02 3.1425e-01 -1.1041e-01 3.5558e-01
1.7370e-01 3.0618e-01 -6.7071e-02 1.8406e-01 6.8487e-01 4.1663e-01
3.0946e-02 -5.0516e-01 -2.8229e-01 -2.8282e-01 2.3254e-01 -2.1508e-01
-8.4610e-02 -3.9999e-02 -3.1937e-01 6.1145e-02 1.9686e-01 -1.1733e-01
-4.5938e-02 -1.4098e-01 -1.0227e-01 3.4548e-01 5.5819e-01 -3.7241e-01
-9.7569e-02 -3.4458e-01 1.7395e-01 -1.4566e-02 -2.8684e-01 -4.1603e-01
-1.0828e-02 4.0514e-01 -3.4146e-01 1.0321e-01 -8.8201e-02 6.7543e-01]
The features corresponding to a text are calculated by averaging the vectors corresponding to the tokens contained it the text. The function below can be used to find out which tokens are not present in the embeddings. The input of the function is a list which contains all the instances. The text is in the second position of an instance. The tokenizer from NLTK is used.
def calculate_vector_repr(data):
'''
Calculates the vector representation of the text. The input of the function
is a list which contains the input (training or testing). The function modifies
this data by adding the representation at the end of each instance.
'''
if debug: not_found = open("not-found.txt", "w")
for instance in data:
text = instance[1]
sentVector = np.zeros(300)
counter = 0
for word in word_tokenize(text):
try:
sentVector += embeddings[word.lower()]
counter += 1
except:
if debug: not_found.write(word + "\n")
if counter:
sentVector = sentVector / counter
instance.append(sentVector)
if debug: not_found.close()
If debug=True calling calculate_vector_repr creates/appends to a file called not-found.txt all the words that are not present in the embeddings. This is very useful for measuring the coverage of the word embeddings. In the case of this task, most of the non found words are either poorly tokenised words or words they are not English.
data = [["dummy", "this is a test"]]
calculate_vector_repr(data)
data
[['dummy',
'this is a test',
array([-1.69022500e-02, 2.87252250e-01, 1.86550750e-02, 1.34868000e-01,
4.24300000e-02, -2.67570750e-01, 2.58480000e-02, -2.83737750e-01,
5.71710000e-02, 2.15382500e+00, -1.57307175e-01, -5.59105000e-02,
-2.40000000e-03, 4.53894500e-02, -9.60605000e-02, -1.85047625e-01,
1.54570000e-02, 1.65845000e+00, -1.73122500e-01, -3.72495000e-02,
-2.85275000e-02, -2.71057750e-01, -4.75250000e-02, 1.30351075e-01,
6.37230000e-02, 2.03934500e-01, 3.63950000e-03, -1.35885500e-01,
4.68250000e-03, -1.42760000e-02, -2.46225000e-04, 8.99967500e-02,
3.52918750e-01, -1.09063000e-01, 4.67625000e-02, 4.68908400e-02,
6.66356250e-02, -6.19975000e-02, -1.38557592e-01, -3.94212250e-01,
2.24767500e-01, 1.93722500e-01, 1.34370750e-01, -9.73465000e-02,
5.74125000e-02, 4.60950000e-03, -2.31309000e-01, 4.35100000e-02,
-1.65817500e-01, 8.05360750e-02, -1.69070000e-01, 2.49950000e-01,
-1.23277500e-02, -7.32342500e-02, 4.79375000e-02, 1.22529500e-01,
8.54340750e-02, 7.20050000e-03, 1.58414650e-01, -2.26668750e-01,
-4.65070500e-02, 1.57557250e-01, -8.18155000e-02, 3.33497000e-01,
3.04625250e-01, -1.29667750e-01, -6.98820000e-02, -1.36443000e-01,
-5.63567500e-02, 2.13260000e-01, 4.11295000e-02, 1.87477500e-02,
2.10122500e-01, 2.84410000e-02, -2.26245000e-02, -9.80845000e-02,
3.33040000e-02, 3.45000000e-05, -2.37012500e-01, 4.54745000e-01,
-3.48975000e-02, -1.04009750e-01, 6.17780000e-02, 2.36718587e-01,
7.68100000e-02, -2.09564500e-01, -2.31786000e-01, -1.67525500e-01,
1.68050000e-01, -1.97675000e-02, -8.27067500e-02, 4.58715000e-01,
-6.05664000e-02, -3.15750000e-02, 6.39547500e-02, 9.35362500e-02,
-5.18382500e-02, -3.98707500e-02, 2.06635250e-01, 2.85175000e-01,
1.55960000e-01, 4.57625000e-02, -1.07550000e-01, -9.50000000e-05,
1.12489250e-01, -8.25805000e-01, 1.29028750e-01, 1.04883500e-01,
-1.27268000e-01, -7.81945000e-02, 7.36750000e-03, -7.81790000e-02,
-2.02637500e-02, -1.34450000e-03, -8.54400000e-03, 1.56997500e-01,
-1.45537500e-01, 3.73980000e-01, 1.38417500e-01, -4.05875000e-02,
-7.90592500e-02, -1.69187250e-01, 3.08477500e-02, -1.67063000e-01,
-7.95925000e-03, 1.61058750e-01, -2.04527500e-01, -2.07422500e-01,
-1.27421250e-02, -7.25512500e-02, -9.06920000e-02, -2.69842500e-02,
-2.09380250e-01, 2.13083500e-01, 1.25434275e-01, -1.76262145e-01,
7.63952500e-02, 3.06730000e-02, 8.89172500e-02, -1.02119500e-01,
-1.19806000e+00, 5.81725000e-02, 1.54513500e-01, 7.77572500e-02,
-1.69317500e-02, -3.48612500e-01, -9.28835000e-02, 3.63925000e-02,
3.26028000e-01, -7.05635000e-02, -6.92765000e-02, 1.33272500e-01,
8.09050000e-02, 1.75165000e-02, 1.17953450e-01, 5.93287500e-02,
-3.31965000e-01, 1.27641750e-01, -8.66400000e-02, -2.57092500e-01,
3.08382500e-02, 2.95660000e-02, 6.91310000e-02, -3.31830000e-02,
-1.73564100e-01, -2.63792500e-01, -8.19967500e-02, 1.17067000e-02,
2.03666773e-01, -6.23300000e-02, 3.38693750e-02, -1.43808000e-01,
1.68575000e-01, -1.03225000e-01, -4.41947500e-01, 4.37812500e-02,
-2.58666250e-02, -9.01300000e-02, -3.02050000e-02, 2.95564750e-01,
-6.80797500e-02, -1.03582500e-01, -1.03924750e-01, -1.36811000e-01,
2.03645000e-02, -1.94859405e-01, -1.80158000e-01, 2.78492500e-01,
-2.19137625e-01, -3.88630000e-02, -2.44470000e-01, -1.10500000e-04,
-5.46747500e-01, 1.68005000e-01, 2.68930000e-01, 2.48715000e-01,
-1.72146250e-01, -9.41317500e-02, 2.36864000e-01, -5.34050000e-02,
-8.16077500e-02, 1.42102250e-02, -3.43040000e-01, 1.20894750e-01,
1.29999250e-01, -5.10635000e-02, -4.50082500e-02, -4.19900250e-02,
1.44472500e-01, 1.34179750e-01, -2.48782500e-01, -8.66902500e-02,
5.88647500e-02, -2.94300000e-01, 5.68540000e-02, 3.07725000e-01,
-4.53325000e-02, 3.26032500e-01, -8.12095000e-02, 1.93018000e-01,
8.21810000e-02, -7.04255000e-02, -6.08912500e-02, -1.65200000e-02,
4.58710000e-02, -1.36672500e-01, -8.41520000e-02, 1.71415000e-01,
-3.06767500e-02, -1.20317250e-01, -5.10400000e-02, 3.44682500e-01,
3.89110000e-02, 1.09950000e-03, -1.77381538e-01, -2.05941125e-01,
3.30971250e-02, -2.76257500e-02, -1.59756000e-01, 2.36192500e-01,
1.62469250e-01, -9.33980000e-02, 1.74687750e-01, 4.63500000e-02,
1.10741000e-01, -1.11376750e-01, 1.30968000e-01, -2.65440000e-01,
-1.22173250e-01, -3.38005000e-02, -6.52402500e-02, -1.30703250e-01,
3.08882500e-02, -5.88427500e-02, 4.71567500e-02, 1.22072250e-01,
3.13256000e-01, -1.90145000e-01, 6.34067250e-02, -5.39375000e-03,
1.88715250e-01, 2.44780000e-01, 1.06738275e-01, -1.66912250e-01,
3.55732500e-02, -1.25672500e-02, 9.57420000e-02, 2.99566400e-01,
6.62767500e-01, 8.87952500e-03, 3.39099250e-01, 2.39295000e-02,
-1.02379000e-01, -1.54405000e-01, -7.59370000e-02, -3.98902500e-02,
-4.68650000e-02, -3.52055000e-02, 1.60293175e-01, 2.04122750e-01,
2.25618750e-01, 2.71627500e-02, -5.58942250e-02, -1.96019250e-01,
-1.39595850e-01, -2.18355000e-01, 7.11065000e-02, -1.21249750e-01,
2.16370000e-01, -2.25518250e-01, -8.21050000e-03, 1.00616350e-01,
2.49310000e-02, -2.06725250e-01, 1.61813250e-01, -7.74647500e-02,
-5.41150000e-03, -8.29525000e-02, -3.95275000e-02, 1.47072925e-01])]]
2.2 Extract sentiment features
The sentiment features are determined using SentiStrength which is able to assign each text a positive and a negative score. In order to facilitate processing, the input files were split into individual files, each containing only one text. The name of each file matched the ID of the text. The following function was used:
def splitData(file_name, train_data = True):
with open(file_name, encoding = 'utf8') as csvfile:
reader = csv.reader(csvfile)
for row in reader:
if train_data:
id_ex, text, label = tuple(row)
else:
id_ex, text = tuple(row)
f = open("split-test/" + id_ex, "w")
f.write(text)
f.close()
A shell script was run to generate the files containing the scores
for f in `find $1 -type f`
do
cat $f | java -jar SentiStrengthCom.jar sentidata ./SentStrength_Data/ stdin > $f.senti
done
After this each file contained two numbers separated by a tab which represented the positive and negative scores.
path_to_sentiment_feats = "senti_feats/"
def getSentiFeatures(instance, path):
'''
Read the sentiment features corresponding to an instance.
Returns a list which contains two elements [positive score, negative score]
'''
f = open(path + instance[0] + ".senti")
line = f.readline()
f.close()
return [int(x) for x in line.strip().split()]
2.3 Calculate the features based on emojis
The assumption is that some emoticons are more likely to indicate a type of aggression or the lack of aggression than others. The emoticons are converted to their corresponding strings description using emoji library.
def getEmojis(text):
"""
Identifies all the emoji in the text using emoji library
"""
return re.findall("(:[0-9a-zA-Z_]+:)", emoji.demojize(text))
The score of each emoji is calculating using TF*IDF with respect to each class. The implementation used in the official submission considered there are 4 classes instead of 3. This was done in order to avoid having a large number of emojis with score 0, which in turn proved to have a negative influence on the evaluation on the dev data.
def getEmojiScores(data):
emos_dist = {'NAG':[], 'CAG':[], 'OAG':[]}
emo_tfidf = {'NAG':[], 'CAG':[], 'OAG':[]}
for instance in data:
emos = getEmojis(instance[1])
for emo in emos:
emos_dist[instance[2]].append(emo)
for key,value in emos_dist.items():
N = len(value)
for emo,f in nltk.FreqDist(value).most_common(50):
tf = f/N
idf = (emo in emos_dist['NAG']) + (emo in emos_dist['CAG']) + (emo in emos_dist['OAG'])
emo_tfidf[key].append((tf * math.log(4/idf), emo))
return {label : {v:k for k, v in emo_tfidf[label]} for label in labels}
We can see which emojis are ranked in top 10 for each class.
from operator import itemgetter
emoji_scores = getEmojiScores(training)
for label in labels:
print("\nLabel:", label)
for em in sorted(emoji_scores[label].items(), key=itemgetter(1), reverse=True)[:10]:
print(emoji.emojize(em[0]), em[0], em[1])
Label: NAG
♥ :heart_suit: 0.10836526343965343
❌ :cross_mark: 0.07126724532517748
💢 :anger_symbol: 0.048813181729573614
😂 :face_with_tears_of_joy: 0.0362641485696259
😯 :hushed_face: 0.018549009057237973
🌟 :glowing_star: 0.017572745422646502
😽 :kissing_cat_face: 0.015620218153463556
🏨 :hotel: 0.013667690884280612
🏯 :Japanese_castle: 0.013667690884280612
⭐ :white_medium_star: 0.012691427249689139
Label: CAG
😂 :face_with_tears_of_joy: 0.14426913454799128
😀 :grinning_face: 0.017123932884034573
😈 :smiling_face_with_horns: 0.009283221168213552
👏 :clapping_hands: 0.009283221168213552
😝 :squinting_face_with_tongue: 0.008251752149523157
🌹 :rose: 0.008251752149523157
👌 :OK_hand: 0.008251752149523157
😜 :winking_face_with_tongue: 0.007705769797815558
📢 :loudspeaker: 0.006188814112142368
🇺🇸 :United_States: 0.006188814112142368
Label: OAG
😂 :face_with_tears_of_joy: 0.108787338322102
🐣 :hatching_chick: 0.062130839714056724
❌ :cross_mark: 0.05436448474979963
😡 :pouting_face: 0.026592460478736046
🃏 :joker: 0.015532709928514181
🌝 :full_moon_face: 0.013591121187449907
💧 :droplet: 0.011649532446385634
😉 :winking_face: 0.008058321357192741
😏 :smirking_face: 0.008058321357192741
😑 :expressionless_face: 0.008058321357192741
For each new text we calculate three features, each corresponding to one of the classes to be predicted. The values of the features are the sum of the emoticons scores appearing in the text for the corresponding class. The values of these three features are normalised by the number of emoticons in the text.
def getEmoFeatures(text, scores):
'''
Returns the features corresponding to the emoji scores
'''
emos_features = {'NAG':0, 'CAG':0, 'OAG':0}
emos = getEmojis(text)
for emo in emos:
for label in labels:
emos_features[label] += scores[label].get(emo, 0)
for label in labels:
if len(emos): emos_features[label]/= len(emos)
return emos_features
The examples below show the features on a few examples.
print(training[289])
['facebook_corpus_msr_429182', 'So humble you are Mukesh Ambani.. your pieces about Entrepreneurs should inspire a generation.. 🙏👍👌', 'NAG']
print(getEmoFeatures(training[289][1], emoji_scores))
{'NAG': 0.007278423690762763, 'CAG': 0.0051764745417459505, 'OAG': 0.0018802749833449726}
print(training[222])
['facebook_corpus_msr_1689985', 'Stupid survey 👎👎👎', 'OAG']
print(getEmoFeatures(training[222][1], emoji_scores))
{'NAG': 0.0, 'CAG': 0.0, 'OAG': 0.005640824950034919}
Train the algorithms
As stated above, the purpose of this method was to investigate whether we can use word embeddings (together with some other features) as features for traditional machine learning algorithms. The data for the ML algorithms is prepared by the extract_XY function. The implementation assumes that the emoji_scores and path_to_sentiment_feats variables are correctly initialised in the global scope.
def extract_XY(data, with_sentiment = 0, with_emojis = 0):
'''
Function which prepares the vectors for the machine learning algorithms
The parameters with_sentiment and with_emojis control whether those
features will be included
Returns X and Y
'''
X = []
Y = []
for instance in data:
features = list(instance[3])
if with_emojis:
features.extend(list(getEmoFeatures(instance[1], emoji_scores).values()))
if with_sentiment:
features.extend(getSentiFeatures(instance, path_to_sentiment_feats))
X.append(features)
Y.append(instance[2])
return X, Y
The following two functions return the model produced by the machine learning algorithms from the training data provided as parameters. The two ML algorithms tried are Support Vector Machine and Random Forest. Each function takes parameters which can tune the performance of the learning algorithm. The values used in the experiments below are the best values determined through a grid search.
def trainSVM(X_train, y_train, c, gamma):
print("Learning ...", end="")
model = SVC(random_state=57, kernel='rbf', C=c, gamma=gamma)
model.fit(X_train, y_train)
print("done!")
return model
def trainRandomForest(X_train, y_train, n_estimators):
print("Learning ...", end="")
model = RandomForestClassifier(n_estimators=n_estimators, max_depth=10)
model.fit(X_train, y_train)
print("done!")
return model
Before we can start experimenting with the ML algorithms we need to calculate the vector representation for the texts. This will modify the training and dev variables. The main reason for implementing the method this way is because deriving the vector representation is time consuming and it shouldn’t be done in the extractXY function.
print("Calculating representation ... ", end="")
calculate_vector_repr(training)
calculate_vector_repr(dev)
print("done!")
Calculating representation ... done!
Use only word embeddings (not reported in the paper)
print("Calculating features ...", end="")
X_train, y_train = extract_XY(training)
X_dev, y_dev = extract_XY(dev)
print("done!")
Calculating features ...done!
SVM, c=2, gamma=0.5
c = 2
gamma = 0.5
model = trainSVM(X_train, y_train, c, gamma)
predicted = model.predict(X_dev)
print(f"SVM with c={c} and gamma={gamma}")
print("accuracy=", np.mean(predicted == y_dev))
print("weighted f-score", f1_score(y_dev, predicted, average='weighted'))
print("Confusion matrix\n", confusion_matrix(y_dev, predicted))
Learning ...done!
SVM with c=2 and gamma=0.5
accuracy= 0.5784738420526491
weighted f-score 0.574230558765779
Confusion matrix
[[587 324 146]
[304 863 66]
[283 142 286]]
Random Forest, n_estimators=180
n_estimators = 180
model = trainRandomForest(X_train, y_train, n_estimators)
predicted = model.predict(X_dev)
print(f"Random forest with n_estimators={n_estimators}")
print("accuracy=", np.mean(predicted == y_dev))
print("weighted f-score", f1_score(y_dev, predicted, average='weighted'))
print("Confusion matrix\n", confusion_matrix(y_dev, predicted))
Learning ...done!
Random forest with n_estimators=180
accuracy= 0.5404865044985006
weighted f-score 0.5132813625882178
Confusion matrix
[[581 425 51]
[282 917 34]
[408 179 124]]
Use word embeddings and emoji scores
print("Calculating features ...", end="")
X_train, y_train = extract_XY(training, with_emojis = True)
X_dev, y_dev = extract_XY(dev, with_emojis = True)
print("done!")
Calculating features ...done!
SVM, c=2, gamma=0.5
c = 2
gamma = 0.5
model = trainSVM(X_train, y_train, c, gamma)
predicted = model.predict(X_dev)
print(f"SVM with c={c} and gamma={gamma}")
print("accuracy=", np.mean(predicted == y_dev))
print("weighted f-score", f1_score(y_dev, predicted, average='weighted'))
print("Confusion matrix\n", confusion_matrix(y_dev, predicted))
Learning ...done!
SVM with c=2 and gamma=0.5
accuracy= 0.5768077307564146
weighted f-score 0.5723505370388843
Confusion matrix
[[585 328 144]
[302 863 68]
[286 142 283]]
Random Forest, n_estimators=180
n_estimators = 180
model = trainRandomForest(X_train, y_train, n_estimators)
predicted = model.predict(X_dev)
print(f"Random forest with n_estimators={n_estimators}")
print("accuracy=", np.mean(predicted == y_dev))
print("weighted f-score", f1_score(y_dev, predicted, average='weighted'))
print("Confusion matrix\n", confusion_matrix(y_dev, predicted))
Learning ...done!
Random forest with n_estimators=180
accuracy= 0.5341552815728091
weighted f-score 0.5079277755736931
Confusion matrix
[[560 434 63]
[279 916 38]
[400 184 127]]
Use word embeddings, emoji scores and sentiment scores
print("Calculating features ...", end="")
X_train, y_train = extract_XY(training, with_emojis = True, with_sentiment = True)
X_dev, y_dev = extract_XY(dev, with_emojis = True, with_sentiment = True)
print("done!")
Calculating features ...done!
SVM, c=5, gamma=0.5 (the best performing setting on unseen Twitter testing data)
c = 5
gamma = 0.5
model = trainSVM(X_train, y_train, c, gamma)
predicted = model.predict(X_dev)
print(f"SVM with c={c} and gamma={gamma}")
print("accuracy=", np.mean(predicted == y_dev))
print("weighted f-score", f1_score(y_dev, predicted, average='weighted'))
print("Confusion matrix\n", confusion_matrix(y_dev, predicted))
Learning ...done!
SVM with c=5 and gamma=0.5
accuracy= 0.5591469510163279
weighted f-score 0.5545043639597993
Confusion matrix
[[533 352 172]
[302 859 72]
[272 153 286]]
Random Forest, n_estimators=160 (the best performing setting on unseen Facebook testing data)
n_estimators = 160
model = trainRandomForest(X_train, y_train, n_estimators)
predicted = model.predict(X_dev)
print(f"Random forest with n_estimators={n_estimators}")
print("accuracy=", np.mean(predicted == y_dev))
print("weighted f-score", f1_score(y_dev, predicted, average='weighted'))
print("Confusion matrix\n", confusion_matrix(y_dev, predicted))
Learning ...done!
Random forest with n_estimators=160
accuracy= 0.5441519493502166
weighted f-score 0.5214229496782077
Confusion matrix
[[568 431 58]
[283 919 31]
[405 160 146]]




