This year, the UK government encouraged supermarkets to display their fuel prices. The scheme is voluntary, and so far only ASDA has started displaying prices on its website. Since fuel prices vary from place to place, you must visit each supermarket’s website to find the best prices near you. To make this process easier, I wrote the following Python script:
# import the necessary modules
import requests
from bs4 import BeautifulSoup
# specify the stores from which to retrieve the prices.
# For each store there is tuple ("Name", "URL")
urls = [
("Sheerwater", "https://storelocator.asda.com/south-east/woking/forsyth-road-sheerwater"),
("Staines", "https://storelocator.asda.com/south-east/staines/chertsey-lane-egham-hythe"),
("Fareham", "https://storelocator.asda.com/south-east/fareham/speedfields-park-newgate-lane"),
]
# retrieve the prices for each place
for place, page_url in urls:
page = BeautifulSoup(requests.get(page_url).text, "html.parser")
postcode = page.find("span", {"class": "c-address-postal-code"})
petrol_prices = page.find_all("div", {"class": "Service-fuelCategory"})
print(f"{place} (Postcode: {postcode.text})")
for petrol_price in petrol_prices:
divs_petrol_price = petrol_price.find_all("div")
print(f"\t {divs_petrol_price[0].text} {divs_petrol_price[1].text}")
print()
Below is the output of the script on 24 Sept 2023:
Sheerwater (Postcode: GU21 5SE)
Unleaded 152.7p
Diesel 157.7p
Staines (Postcode: TW18 3LS)
Unleaded 149.7p
Diesel 153.7p
Fareham (Postcode: PO14 1TT)
Unleaded 154.7p
Diesel 155.7p
The output also contains the postcode of the shop because you may want to check how far it is from you, so you can decide whether you are really going to save money.
I made the code available in Google Colab, so you can run it there.
How does it work?
If you are only interested in getting the latest prices, you can stop here. However if you want to understand how it works, read on.
The program uses the BeautifulSoup library to extract information from a webpage. The page is first downloaded using the requests library.
In order to identify the bits of information we need, we need to analyse the structure of the webpage. This can be done easily by using the Inspect option in Google Chrome on the information we need to extract. If we do this for the postcode, we see that it appears in a span with the class c-address-postal-code.
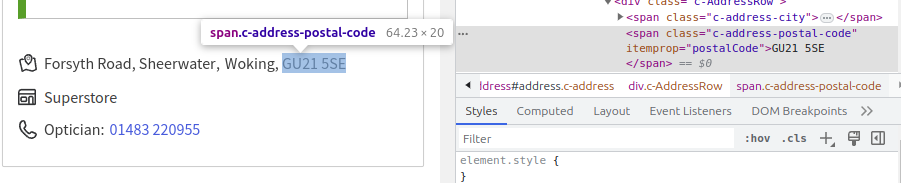
Therefore, the postcode can be extracted using
postcode = page.find("span", {"class": "c-address-postal-code"})
There is only one postcode on the page, so we access it using postcode[0].
The same approach can be used to extract the petrol prices. The structure for the price is a bit more complicated:

The price is wrapped in a div with the class Service-fuelCategory which contains two divs. The first div contains the type of fuel (unleaded) in the example above. The second div contains the actual price.
To retrieve the prices, I first find the divs with the class Service-fuelCategory:
petrol_prices = page.find_all("div", {"class": "Service-fuelCategory"})
Because there are several types of fuel available (usually two: unleaded and diesel), I need to iterate through each type of fuel.
for petrol_price in petrol_prices:
The webpage is very nicely structured, so I don’t do any further checks. I just retrieve the divs inside the petrol_price and display the type and price.
divs_petrol_price = petrol_price.find_all("div")
print(f"\t {divs_petrol_price[0].text} {divs_petrol_price[1].text}")
One problem with web scrapping is that scripts work as long as there are no changes to the structure of the website. If ASDA decides to change the structure, the script may stop working.
This work by Constantin Orasan is licensed under Attribution-ShareAlike 4.0 International![]()
![]()
![]()




